Metaphors can help. We don’t regulate highways the same way we regulate sports cars or school buses. So why should we talk about regulating “AI” like it’s a single thing?
Here’s a better way: think of the AI ecosystem as made up of four key components — cars, roads, buses, and traffic laws. This metaphor gives us a much clearer sense of where government should act, and just as importantly, where it shouldn’t.
The Framework: Mapping the AI Ecosystem
Press enter or click to view image in full size
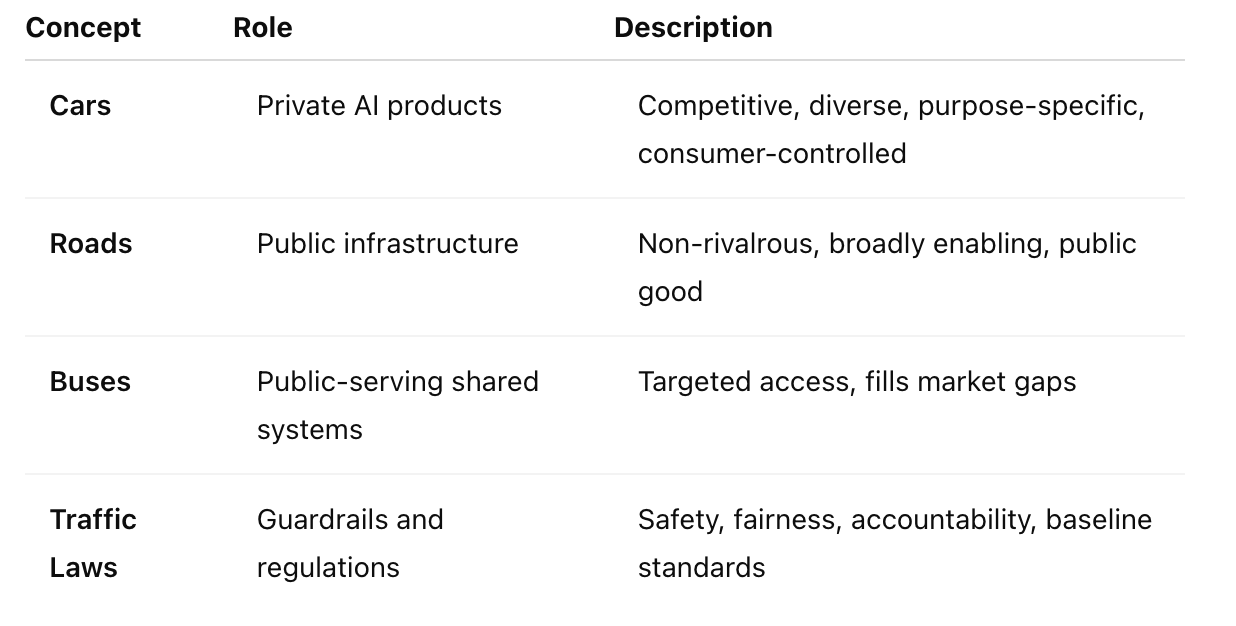
Cars are like ChatGPT, Claude, Midjourney, or domain-specific prediction tools in finance or healthcare. The market thrives on competition and diversity here. We want lots of options built for different needs. Government should regulate for safety, not build the engines.
- Roads are the open-access infrastructure that makes innovation possible — datasets, open-source models, interoperability standards. The private sector underinvests in these because they benefit everyone. Government should step in here.
- Buses are the AI tools built or funded by the public sector for public needs: think medical support for rare conditions or tools to navigate complex public systems like taxes or housing. These exist where private incentives fall short.
- Traffic Laws are the baseline guardrails that apply to everyone — factual accuracy in critical domains, child safety standards, content restrictions. They set the rules of the road without picking winners.
How the Metaphor Helps Us Make Better Decisions
Public Roads: Open Infrastructure for Innovation Public investment should go toward foundational infrastructure like high-quality training datasets, especially in underrepresented domains (e.g., rare languages or public health). These are the roads AI travels on. They’re often invisible to users but essential for the whole system to function.
Some open-source base models might also fit here. They aren’t tailored to specific needs but serve as starting points for innovation — like roads that lead to different destinations.
Private Cars: Let the Market Compete The market is great at building diverse, purpose-built models and applications. From legal summarization tools to recipe assistants, medical diagnostics, financial forecasting systems, and image or video generation tools, the diversity of “cars” is a feature, not a bug. We don’t want the government designing the next minivan or image diffusion model.
What we do want are smart traffic laws to ensure these tools are safe and fair. But the government shouldn’t try to build or compete in this layer directly — just as it doesn’t manufacture vehicles.
Public Buses: Fill the Gaps Where Markets Don’t Some needs won’t be met by the market. Think of medical AI for rare diseases — low commercial return, high social value. Or government services made navigable through AI — tax filing help, housing aid, legal guidance.
These aren’t replacements for private tools. Just like buses don’t replace cars, they offer equitable access to essential services.
Traffic Laws: Guardrails for a Shared System Some things need universal rules: adversarial robustness, child safety, misinformation, copyright compliance. These are the seatbelts and stop signs of the AI world. They don’t limit innovation — they make the whole system work better.
Good traffic laws don’t pick winners. They ensure safety while allowing a wide range of vehicles (and drivers) to share the road.
Why This Framework Matters — And How to Use It
Many people don’t trust “big tech” to build AI that is in the best interest of society — or just don’t trust them at all. But before we start talking about the role government or public AI should play, we need to clarify what we mean. Are we talking about government-run AI? Open-access tools? Rules and oversight?
This framework helps clarify those questions:
- Should we regulate this model? (Car)
- Should we fund this tool as infrastructure? (Road)
- Should we ensure this capability is accessible to underserved communities? (Bus)
- Do we need new rules to keep people safe? (Traffic laws)
Rather than vague calls for government to “do more,” it invites sharper, more targeted questions — and encourages a smart division of labor between public and private actors. We don’t need the government to “build AI” — we need it to pave the roads, enforce the rules, and run the buses that help everyone get where they need to go.
By separating the roles of infrastructure, market competition, public access, and regulation, we can build an AI ecosystem that’s not just powerful, but also fair, inclusive, and sustainable. Let’s stop asking if government should “do more on AI.” Let’s ask what part of the AI stack we’re talking about — and whether it fits best as a car, a road, a bus, or a traffic law.
]]>